Hadoop伪分布式环境搭建
环境说明:VM上ubuntu 16.04版本
安装hadoop前的准备
(1)ssh 免密登录
(2)配置好Java环境
第一二步骤的安装见网上博客
安装Hadoop
下载hadoop
到上一篇博客给出的网下载hadoop-0.20.2.tar.gz,到随便一个目录解压,我这里是解压到了/zoux目录,并将hadoop-0.20.2重名为hadoop
编辑配置文件
进入hadoop/conf目录下,编辑core-site.xml文件
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>编辑hdfs.site.xml文件
下面需要注意data目录是存放Hdfs文件的目录,需要自己提前建立,并使hadoop有权限操作它
(方法:sudo chmod 777 -R data,将data目录的权限设置为777)
<property>
<name>dfs.data.dir</name>
<value>/zoux/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>编辑mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>接下来还有一个重要的配置文件 hadoop-env.sh, 这里只要配置java的环境变量即可:
export JAVA_HOME=/java/jdk1.8.0_171这里/java/jdk1.8.0_171是我前面配置java的环境变量。
设置hadoop环境变量
打开/etc/profile文件, 末尾加入这俩句话即可。 /zoux/hadoop是解压完重命名的目录
export HADOOP_HOME=/zoux/hadoop
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin然后输入 source /etc/profile是配置文件生效。
这时命令行输入 hadoop -version,出现版本号信息就行。(我这里出现的事java的版本,但是后面的hadoop命名是生效的)
接下来我们需要格式化hdfs目录
输入 hadoop namenode -format
上一步成功后我们需要判断集群是否能正常启动
(1) 在/zoux/hadoop目录下 输入 bin/start-all.sh启动集群

这是正常的运行目录,这一步并不是成功,如果log的输出都是正常的话,就成功了。
如果遇到以下的问题
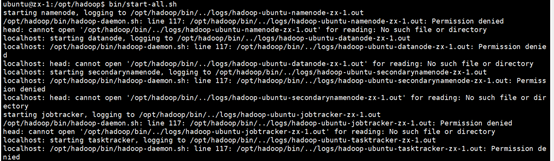
这是logs目录的权限太大,hadoop命令写不进去。这时使用下面的命令将logs文件夹权限降下了就可以了。
sudo chmod -R 777 logs (2)在 bin/start-all.sh没有报错后,输入jps查看所有的进程
3222 SecondaryNameNode
5707 Jps
3099 DataNode
3419 TaskTracker
2974 NameNode
3295 JobTracker 出现上面这些进程表示集群安装成功。恭喜你,进入下一步开发了。
(3)bin/stop-all.sh关闭集群